UN GRANDE CORPUS DI ITALIANO GIORNALISTICO
Guy Aston e Lorenzo Piccioni
Universit� di Bologna
Unlike other major European languages, Italian
has a dearth of large contemporary corpora that can be freely interrogated for
teaching and research purposes. This paper describes the procedures being
employed to create a 400-million word corpus of newspaper articles from La Repubblica, encoded in XML following the norms of the Text
Encoding Initiative. The corpus, which is currently 40% complete, can be
interrogated with the SARA program originally developed for use with the
British National Corpus. Illustrations are provided of ways in which it can
provide linguistic and cultural information of various types, and possible
future refinements are outlined.
1��������� Introduzione
Alla Scuola Superiore di Lingue Moderne per Interpreti e Traduttori dell�Universit� di Bologna (SSLMIT) esiste una tradizione ormai decennale di utilizzo di corpora nella ricerca e nella didattica. Per chi deve tradurre, i corpora rappresentano fonti impareggiabili di informazioni linguistiche (Bernardini & Zanettin 2000). Per alcune lingue europee, corpora elettronici di grandissime dimensioni sono da tempo disponibili. Per l�inglese superano i 100 milioni di parole il Bank of English e il British National Corpus, per il francese Le tr�sor de la langue fran�aise, per lo spagnolo il Corpus de Referencia del Espa�ol Actual, per il tedesco i Mannheimer Korpora presso l�Institut f�r Deutsche Sprache. Per l�italiano invece, non esiste alcun corpus di dimensioni analoghe, se si eccettua il CORIS, tutt�ora in fase sperimentale, che non permette tuttavia all�utente di accedere ai testi che lo compongono, n� di sapere le fonti delle citazioni proposte (Rossini Favretti et al, in stampa). L�assenza di un corpus di italiano contemporaneo pienamente accessibile ha impedito a nostri docenti e studenti di effettuare studi comparativi con le lingue straniere da e nelle quali traducono.
Nella primavera del 2001, il quotidiano La Repubblica ha messo in vendita 16 CD-ROM contenenti tutti gli articoli pubblicati fra il 1985 e il 2000 (esclusi supplementi, fotografie, pubblicit�, tabelle ed elenchi vari). Sebbene provenienti da un�unica fonte e appartenenti esclusivamente all�ambito giornalistico, questi sembravano costituire una base potenziale per un corpus di dimensioni notevoli, e di facile costruzione. Coprendo un arco di 16 anni, tale corpus poteva fornire uno strumento per lo studio diacronico oltre che sincronico dell�italiano contemporaneo, nonch� per studi contrastivi (sono gi� disponibili corpora di testi giornalistici per molte altre lingue). Abbiamo pertanto chiesto il permesso di estrarre i testi dai CD-ROM e di costituirli in un corpus per usi didattici e scientifici; permesso che Repubblica ci ha gentilmente concesso. In questa relazione illustriamo la procedura seguita per la creazione del corpus, e diamo alcuni esempi di applicazioni possibili.
�
2��������� Procedura
Ciascun CD-ROM
contiene una banca dati all�interno della quale sono memorizzati i testi degli
articoli pubblicati in quell�anno, nonch� varie informazioni di tipo
metatestuale (data, pagina, ecc.). Per raccogliere i testi in un unico corpus
che copri l�intero arco di 16 anni, � pertanto necessario estrarre i singoli
articoli dalle banche dati, assieme alle informazioni metatestuali relative, e
convertirli in un formato adatto per un corpus. Essendo i tipi di codifica
utilizzati nei vari CD parzialmente diversi, � anche necessario regolarizzare i
testi e le informazioni metatestuali in base ad uno standard unico.
Una stima approssimativa indicava che ogni annata del giornale poteva contenere 25 milioni di parole circa, prefigurando un totale di 400 milioni di parole nei 16 anni - dimensioni raggiunte da pochissimi corpora esistenti. Prima di creare il corpus, era pertanto necessario identificare degli strumenti in grado di memorizzare e interrogare una tale mole di dati. Un programma di interrogazione �free text�, che percorre tutti i testi alla ricerca di soluzioni, avrebbe comportato tempi di interrogazione troppo lunghi. Occorreva invece indicizzare il corpus, in modo che il programma di interrogazione potesse gi� identificare nell�indice le posizioni delle soluzioni da recuperare. A questo scopo era di buon auspicio la disponibilit� di una nuova versione di SARA, il software di interrogazione sviluppato per il British National Corpus (BNC: Aston & Burnard 1998), in grado di indicizzare qualsiasi corpus codificato in XML secondo le norme internazionali della Text Encoding Initiative (TEI: Sperberg-McQueen & Burnard 2002). SARA � un software client-server, ove il corpus indicizzato si trova su un server centrale, e viene interrogato via rete dal computer dell�utente, dove deve essere presente il programma client di interrogazione. L�impiego di SARA avrebbe permesso a molti utenti del nuovo corpus di consultarlo attraverso uno strumento con il quale erano gi� familiari, data la loro esperienza con il BNC, nonch� la gestione del server tramite un sistema amministrativo gi� collaudato. Fatto un calcolo approssimativo dello spazio necessario per la memorizzazione del corpus e la sua indicizzazione con SARA, stimato complessivamente in 30-40GB, abbiamo acquistato un disco da 72GB da montare sul server principale della Scuola.
�La realizzazione del corpus si � articolata su cinque fasi principali:
- estrazione degli articoli e delle
relative informazioni metatestuali dalle banche dati sui CD;
- regolarizzazione di questi testi;
- loro raggruppamento in file;
- codifica in XML, seguendo le norme TEI;
- indicizzazione del corpus con SARA.
Indicizzazione
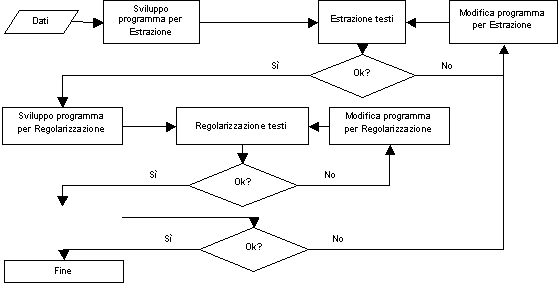
Ciascuna di queste fasi ha comportato lo sviluppo di procedure
specifiche, che andavano pian piano sperimentate e perfezionate. Per capire
meglio il processo, si riporta il diagramma di flusso relativo (Fig. 1).
Queste operazioni
sono state completate per le prime sette annate del corpus (1985-1991), per le
quali si riportano alcune caratteristiche di base in Tab. 1.
�
|
annate |
7 |
|
numeri del
giornale |
2.085 |
|
articoli |
224.140 |
|
frasi |
6.316.532 |
|
parole (tokens) |
141.194.072 |
|
parole (types) |
581.113 |
Tab. 1. Composizione del corpus provvisorio Reptry
2.1������ Estrazione dei testi
La condizione necessaria per la
creazione di un corpus consultabile tramite SARA era la disponibilit� di un
insieme di file contenenti testo in formato ASCII. Questa assunzione,
apparentemente scontata nella sua semplicit�, solleva due problematiche.
Il problema principale consiste
nell�ottenere da un insieme di dati binari (i database contenuti nei CD-ROM)
una serie di testi in formato ASCII, su cui lavorare per produrre materiale
testuale indicizzabile e utilizzabile dal server SARA. Il secondo problema,
decisamente pi� subdolo, � dovuto allo status di applicazione in costante
sviluppo di SARA: ci� determina una frequente indecisione, legata al fatto che
l�analisi dei risultati deve tenere in considerazione allo stesso tempo errori
prodottisi durante il processo di trasformazione e comportamenti non sempre
ineccepibili del software di indicizzazione e consultazione.
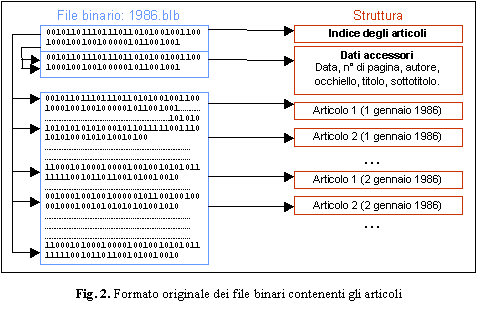
Il supporto originario � composto di 16 CD-ROM contenenti ciascuno la raccolta degli articoli pubblicati in un anno sul quotidiano. Le raccolte di articoli sono organizzate in file binari di grandi dimensioni di formato inizialmente sconosciuto.
La prima fase del lavoro consisteva nell'identificare correttamente le informazioni contenute in questi file, quali informazioni fossero effettivamente presenti e come queste fossero strutturate, per sviluppare un software che fosse in grado, con un procedimento il pi� possibile automatizzabile, di estrarre e ristrutturare le informazioni in una forma consona alle nostre esigenze.
Da un'analisi dei file, effettuata principalmente considerando ripetizioni e ricorrenze, siamo riusciti ad estrapolarne la struttura. Come � possibile vedere in Fig. 2, i file contengono una prima intestazione, che fornisce un'indicazione sulla posizione di ogni articolo all'interno del file, una seconda intestazione, che contiene i dati accessori di ogni articolo (nome dell'autore, titolo, sottotitolo e occhiello, data e numero di pagina del quotidiano nel quale � apparso l'articolo) e, di seguito, tutti gli articoli in ordine cronologico. Altre informazioni, sicuramente interessanti, quali la categoria dell'articolo e la titolazione della pagina non sono incluse nel database ma sono contenute nel programma originale di consultazione, e quindi inaccessibili.
Gli articoli sono strutturati come una sequenza di caratteri che costituiscono il corpo del testo intercalato da punteggiatura, assolutamente privo di formattazione, suddivisione in frasi e in paragrafi.
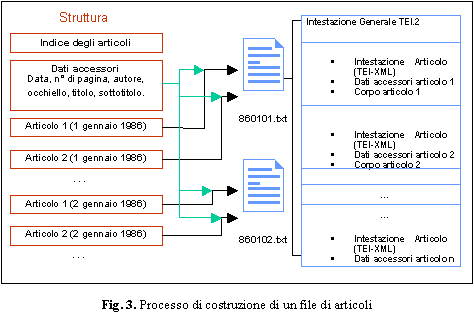
Una volta identificata la struttura dei database contenenti gli articoli si � potuto procedere con la loro ristrutturazione in file di testo. Il risultato ottenuto � esemplificato in Fig. 3: ogni testo prodotto � il risultato dell'unione di tutti gli articoli pubblicati su un numero del giornale e di intestazioni nelle quali sono state inserite tutte le informazioni accessorie disponibili per ogni articolo.
2.2������ Regolarizzazione
Risolto il problema dell�estrazione
degli articoli, rimane quello, non meno spinoso, della loro regolarizzazione.
Una corretta indicizzazione � subordinata:
- all�identificazione delle occorrenze di una parola nell�ambito dell�intero corpus;
- ad una corretta individuazione dei vari componenti del testo.
2.2.1��� Identificazione delle parole
Passando ad un esempio pratico, in fase di consultazione del corpus,
ricercando le occorrenze della parola acchiapp�,
diverse trascrizioni come acchiapp�, (acchiapp�, l'acchiapp� o ACCHIAPPO' devono
essere correttamente individuate, mentre forme del tipo acchiappo o 'acchiappo'
devono essere ignorate in quanto non pertinenti. Altri problemi legati alla
corretta individuazione vengono sollevati dalla rappresentazione abbreviata
delle annate (anni '80; nel '700), dagli intervalli temporali (� arrivato in 1'35''; 35'' di distacco), dalle parole
straniere e non (l'�tat c'est moi; rock 'n' roll; 'ndrangheta). In tutti questi casi il problema consiste nel capire
se il simbolo �
deve essere considerato apostrofo o accento, o se deve essere identificato in
altro modo (per esempio come delimitatore di citazione o espressione di un
lasso di tempo).
A tutto questo si aggiunge l�evoluzione a cui � andato incontro negli anni il word processing, che ha reso disponibile un sempre maggior numero di possibilit� per quello che riguarda la rappresentazione dei caratteri e la formattazione di blocchi di testo. Questa evoluzione, che ha permesso una sempre migliore rappresentazione dei testi scritti, ha prodotto come risultato la mancanza di uno standard nella codifica utilizzata nei CD. Ci� si traduce, per esempio, nell�impossibilit� di distinguere automaticamente discorso diretto, citazioni e �cosiddetti� all�interno degli articoli pubblicati nei primi anni (le tre entit� vengono trattate formalmente allo stesso modo, racchiudendole tra apici singoli) mentre, nelle pubblicazioni pi� recenti � visibile una distinzione netta fra di esse, tramite l�utilizzo di delimitatori differenti (' ', " ", � �).
Se ai problemi fino ad ora illustrati si aggiunge il fatto che i primi testi sono sicuramente stati scansionati a partire da originali cartacei, e che la conversione in formato elettronico ha indotto un grande numero di errori legati al riconoscimento (OCR), si avr� un�idea della complessit� della situazione.
Queste caratteristiche, non problematiche dal punto di vista del cervello umano che, educato da anni di utilizzo della lingua, non incontra alcuna difficolt� durante il processo di scomposizione delle parti del discorso, diventano invece problemi insormontabili (se non risolti) dal punto di vista di una macchina, che non � in grado a priori di associare diverse rappresentazioni alla stessa sequenza di caratteri.
Le diverse fasi del lavoro effettuato per standardizzare il riconoscimento delle parole sono illustrate di seguito.
�
Identificazione e correzione degli accenti
a.
Nei testi
estratti le lettere accentate vengono rappresentate di volta in volta
utilizzando o il carattere preposto, o il carattere corrispondente senza
accento seguito dall�apostrofo. Consideriamo l�esempio frequente di perche' e perch�: per evitare che le due forme vengano indicizzate come se
fossero diverse, la forma perche' va
ricondotte alla forma perch�. Cos�
per tutti i casi, escludendo quelli in cui l�apostrofo compare come
delimitatore di una citazione. Per fare un altro esempio, l�espressione 'E' ancora in vita' andr� trasformata in
'� ancora in vita' e non in '� ancora in vit�; tutti questi casi
devono essere identificati ed eventualmente corretti in fase di
pre-elaborazione del testi.
b.
La direzione
dell�accento varia in molti casi
da testo a testo: insieme a perch� troviamo perch�. Sebbene tale variazione potrebbe riflettere
differenze socio-geografiche, abbiamo deciso di regolarizzare la direzione
degli accenti seguendo gli standard nazionali, in modo da permettere l�utente di trovare facilmente tutte le
occorrenze della parola.
c.
Nei titoli,
sottotitoli e occhielli degli articoli le lettere accentate compaiono sempre
nella forma non accentata seguite dell�apostrofo (es: CITTA�); queste forme vanno necessariamente ricondotte alla forma
accentata.
�
Identificazione di virgolette, apostrofi,
tempi
Un simbolo di apostrofo pu� identificare differenti situazioni:
a.
un accento
(cfr. sopra);
b.
un lasso di
tempo (1'23'');
c.
un delimitatore
di citazione, discorso diretto, o �cosiddetto�;
d.
un apostrofo
vero e proprio.
Queste quattro situazioni vanno identificate correttamente e trattate
in modi differenti. Se si tratta di un accento (a) dovr� essere trasformato in
una lettera accentata come visto in precedenza. Se di un lasso di tempo (b), o
un delimitatore di citazione (c), dovr� essere trasformato in modo che non
possa essere ambiguamente indicizzato come apostrofo (come vedremo in seguito).
Se si tratta di un apostrofo in senso stretto il problema consister� nel capire
se appartiene alla parola che lo precede (vorremmo che l'uomo fosse indicizzato come due parole: l' e uomo) o a quella che
lo segue ('ndrangheta, anni '80, l'inglese it's).
�
Identificazione di delimitatori
L�indicizzazione
richiede l�uso coerente di
delimitatori della parola, quale lo spazio e la punteggiatura, per evitare che
questi vengano interpretati come parte della parola stessa. A tal fine si �
deciso di introdurre uno spazio fra due parole legate da un apostrofo (l'
uomo), e fra punteggiatura iniziale e la parola successiva (la "
parte").
�
Correzione manuale dei titoli
I titoli degli articoli sono stati in gran parte corretti manualmente,
a causa del gran numero di errori (principalmente legati all�uso delle
virgolette), e dello standard di rappresentazione delle parti della frase,
differente da quello utilizzato per il corpo degli articoli..
- Sostituzione
dei caratteri �speciali�
Per caratteri speciali si intende l�insieme dei caratteri che esulano
dalla rappresentazione standard dei simboli dell�alfabeto, quali le lettere
accentate, i puntini di sospensione, i caratteri utilizzati per racchiudere
citazioni, cosiddetti, discorso diretto, ecc. Questi caratteri devono essere
sostituiti per due motivi:
a.
I sistemi
informatici hanno tabelle di rappresentazione dei codici di carattere
differenti da sistema a sistema (es: se A e B sono due sistemi informatici, �
possibile che A rappresenti il codice utilizzato per la ��� correttamente, e il
sistema B lo rappresenti con un carattere che nulla ha a che fare con la ���).
Questo problema � stato risolto assumendo uno standard (ISO8859-1 o ISO
Latin 1) che definisce delle entity
references che ogni sistema traduce nella sua personale rappresentazione
del carattere indicato.
b.
Caratteri
uguali utilizzati per scopi diversi vanno differenziati a livello di
indicizzazione. Per fare un esempio, i caratteri " e ', che possono di volta in volta indicare citazioni,
tempi, classifiche, sono distinguibili a livello di ricerca sul corpus solo con
un�adeguata differenziazione della loro rappresentazione interna per permettere
all�indicizzatore di trattarli come differenti.
|
carattere |
nome |
entity reference |
|
' |
apostrofo |
' |
|
" |
inizio citazione |
&bquo; |
|
" |
fine citazione |
&equo; |
|
' |
minuti |
′ |
|
" |
secondi |
″ |
|
� |
puntini di sospensione |
… |
Tab. 2. Estratto della tabella dei caratteri ISO8859-1 (ISO
Latin 1)
2.2.2��� Identificazione di frasi, titoli e paragrafi
Il secondo presupposto per una corretta indicizzazione con
SARA richiede la codifica in formato TEI-XML dei testi del corpus. Una codifica
di questo tipo � tanto pi� utile quanto pi� sono dettagliate le informazioni
estrapolabili dai testi. Il caso ottimo � rappresentato da un insieme di testi
in cui ad ogni �parte� �
associata una funzione linguistica. Per �parte�
si intende un qualsiasi sottoinsieme del testo, che pu� essere costituito dal
testo intero fino alla singola parola. Per ottenere una codifica di questo
tipo, ogni �parte� viene
etichettata, inserendo all�interno del testo appositi tag che forniscono
informazioni sulla �parte�
associata.
Identificare correttamente frasi, titoli e paragrafi all�interno di un testo consente di informare l�indexer della presenza di un�ulteriore suddivisione del testo in unit� di dimensione inferiore: questa operazione rende possibili ricerche ristrette all�ambito della singola unit� in fase di consultazione del corpus. Nei testi originali contenuti nei CD-ROM, purtroppo, non esiste alcuna indicazione relativa alla suddivisione del testo, eccezion fatta per il titolo, svincolato dal corpo del testo e memorizzato separatamente. Pertanto si � dovuto trattare il testo di ciascun articolo come un unico paragrafo.
L�unica altra suddivisione estrapolabile � rappresentata dalle frasi
che, pur non essendo esplicitamente indicate, sono comunque individuabili in
quanto delimitate. I
delimitatori di una frase sono rappresentati tradizionalmente dai simboli di
punteggiatura (punto, punto esclamativo, punto interrogativo, puntini di
sospensione); ma nel nostro caso, la pratica si � rivelata di tutt�altra
natura. Ad esempio, n� il punto n� il punto interrogativo (anche se
seguiti da spazio e carattere maiuscolo) indicano sempre la fine della frase.
Per questo � stato necessario stilare una lunga lista di eccezioni con regole
specifiche, relative ad abbreviazioni, iniziali, numeri, incisi, parentesi,
citazioni, puntini di sospensione, ecc.
Le eccezioni pi� frequenti erano dovute a:
a.
errori commessi
durante la stesura o l�acquisizione dei testi, eliminabili solo mediante
revisione manuale dei testi;
b.�� Sigle, abbreviazioni, orari, importi, ecc� (es: Regio decreto n. 1827; ecc. ecc.);
c.�� Punti interrogativi e puntini di sospensione presenti all�interno
di una frase.
Lo sviluppo di algoritmi in grado di identificare in maniera sufficientemente affidabile le frasi all�interno del corpo del testo ha richiesto molto pi� lavoro del previsto, e si � dovuto rinunciare all�analisi in frasi dei titoli, ove mancava spesso qualsiasi indicazione di punteggiatura. Non potendo effettuare un�analisi manuale, si � deciso di indicare come fine frase la fine di ciascun titolo, operando ulteriori divisioni all�interno di questo nei soli casi in cui un elemento di punteggiatura fosse presente, tenendo conto sempre della lista di eccezioni.
2.3������ Raggruppamento in file
In ogni file sono
stati raggruppati tutti gli articoli pubblicati in un numero del giornale,
stimando un totale di circa 5000 file per i 16 anni. Poich� ciascun articolo
costituisce un testo independente ai fini della maggior parte delle analisi
linguistiche, sarebbe stato auspicabile inserire ciascun articolo in un file
diverso. Questa strada era comunque difficilmente praticabile visto che avrebbe
portato il numero di file a mezzo milione circa, richiesto uno spazio disco pi�
grande per la memorizzazione dei testi e dell�indice, e allungato i tempi di risposta in fase di interrogazione. A
questo limite si � cercato di rimediare attraverso la divisione interna di ciascun
file in articoli, indicati attraverso una codifica analoga a quella utilizzata
per titoli, paragrafi e frasi.
2.4������ Codifica TEI- XML
2.4.1��� Elementi
Le norme TEI offrono delle linee guida per la codifica di corpora a diversi livelli di profondit�. Date le dimensioni del corpus, e la scarsezza di tempo e di risorse umane, abbiamo deciso di limitare la codifica ai soli elementi gi� codificati in qualche maniera nei CD, o comunque identificabili attraverso procedure automatiche. I primi comprendevano la data e pagina di pubblicazione di ciascun articolo, i titoli (di vari tipi: head, subhead, byline, ecc.), e il corpo dell�articolo (in quest�ultimo non era riportata, purtroppo, la divisione in paragrafi). Fra gli elementi riconoscibili automaticamente, si � scelto di identificare e numerare (a) gli articoli e (b) le frasi, sia per permettere ricerche di co-occorrenze all�interno dello stesso articolo o della stessa frase, sia per facilitare i riferimenti nelle concordanze.
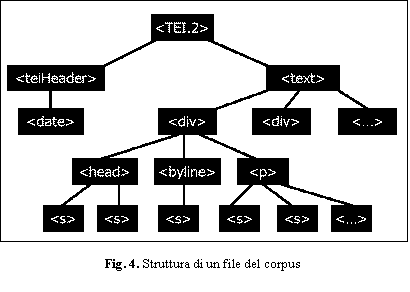
Le norme TEI richiedono che ciascun file sia costituito da un elemento
<TEI.2> con una sua struttura interna ad albero. Al primo livello, un
elemento <TEI.2> deve contenere un <teiHeader>, che fornisce tutte
le informazioni metatestuali relative ad un elemento <text> che lo segue.
Poich� ogni file corrisponde ad un numero del giornale, il <teiHeader>
contiene la data di pubblicazione, oltre ad una serie di informazioni
riassuntive del contenuto (nome del file, procedure editoriali, numero di
articoli, numero di frasi, numero di parole ecc.). L�elemento <text>
contiene una serie di <div>, ciascuno dei quali corrisponde ad un
articolo. I <div> sono a loro volta suddivisi in vari <head>, un
<byline> (che indica l�autore) e un <p> (il corpo del testo) - suddivisi
a loro volta in frasi (<s>). La struttura di ciascun file risulta
pertanto come in Fig. 4.
L�inizio di ciascun elemento in questa struttura viene
indicato da uno start-tag fra parentesi ad angolo, contenente il nome
dell�elemento ed eventuali attributi specifici, e la sua fine con un end-tag,
contentente il nome dell�elemento preceduto dalla barra (/). Ci� porta alla
creazione di file del tipo in Fig. 5.
<TEI.2 id=�XDH�>
<teiHeader> �
<date>sabato 21 aprile 2006</date> � </teiHeader>
<text>
<div id=�XDH001�
n=�1� type=�article�>
<head type=�main�><s
n=�001�> Attentato contro la linguistica.</s></head>
<head type=�sub�><s
n=�002�> Bloccata la didattica in
facoltà.</s></head>
<byline><s n=�003�> Marcella
Arrostita.</s></byline>
<p>
<s n=�004�> Il fumo si leva ancora dai ruderi dell'
aula magna.</s>
<s n=�005�> &bquo; È incredibile
… mi mancano le parole
&equo;, ripete il professore fra le lacrime.</s>
��
</p>
</div>
<div id=�XDH002�
n=�1� type=�article�> �� </div>
</text>
</TEI.2>
Fig. 5. Un articolo codificato. Gli a capo, le rientranze e le variazioni di
font sono assenti dalla versione elettronica. Le sequenze �&xxx;�
indicano entit�, in sostituzione di caratteri particolari (accenti, virgolette,
tratti, puntini, ecc.: cfr. 2.2.1 sopra).
2.4.2��� Attributi
Fra i vari attributi
degli elementi (indicati in corsivo in Fig. 5), l�attributo id indica il
nome del file nell�elemento <TEI.2> (cfr. 2.5 sotto), e il nome del file
seguito dal numero dell�articolo nell�elemento <div>. L�attributo n
dell�elemento <div> indica il numero di pagina di pubblicazione, mentre
quello dell�elemento <s> indica il numero sequenziale della frase
all�interno del file. L�attributo
type dell�elemento
<div> � obbligatorio per il software di consultazione SARA, e potr�
servire per introdurre un�eventuale
categorizzazione degli articoli in una fase successiva del lavoro.
La codifica minima utilizzata rimane comunque estendibile in un momento successivo, qualora si trovassero le risorse per - ad esempio - un�analisi grammaticale con classificazione morfosintattica di ciascuna parola (POS tagging: cfr. 4 sotto), oppure semplicemente per indicare i nomi propri come <name>, o le espressioni in lingua straniera come <foreign>.
2.4.3��� Indicizzazione
L�indicizzazione di un corpus di queste dimensioni con SARA richiede
notevoli risorse computazionali, e la dimensione dell�indice (da tre a cinque
volte quella dei testi) � tale da richiedere ogni sforzo di minimizzazione,
anche per ridurre poi i tempi di risposta ad interrogazioni. A questo scopo sono
stati assegnati nomi di solo tre caratteri a ciascun file - il primo che indica
l�anno, il secondo il mese, e il terzo il giorno del mese di quel numero del
giornale. Questi file sono stati poi organizzati in cartelle seguendo la
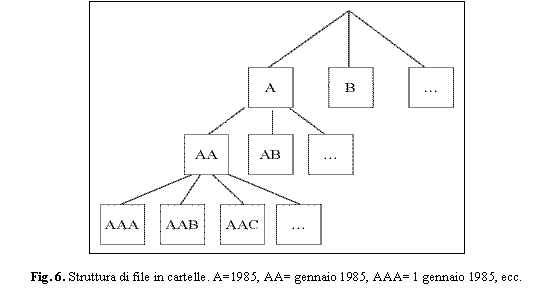
struttura in Fig. 6.
Anche con questi accorgimenti, per indicizzare i 2000 file dei sette anni 1985-91 sono state necessarie pi� di 24 ore di calcolo da parte di un sistema Linux di notevole potenza.
3.�������� Alcuni esempi di uso
3.1������ Caratteristiche del software di interrogazione
SARA permette di
cercare all�interno di un
corpus:
- le occorrenze di singole parole o
sintagmi (utilizzando anche wildcard), o di elementi TEI/XML
(<teiHeader>, <date>, <text>, <div>, <head>,
<byline>, <p> ,<s>, ecc.), anche con particolari
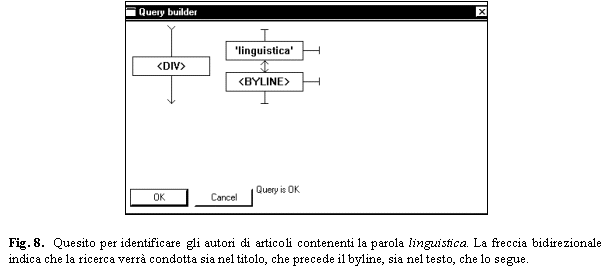
attributi. Cos� si possono cercare occorrenze del sintagma �buona
giornata� o �modo di dire�, di parole che iniziano con la stringa
�divamp�, o dell�elemento <s> (il numero di soluzioni
corrisponderebbe al numero di frasi nel corpus). � inoltre possibile
limitare una ricerca al contenuto di un elemento TEI (anche con specifici
attributi). Pertanto si possono cercare occorrenze di �La Scala� in un
titolo, di �Scalfari� in un <byline>, di �01 aprile� in una
data, di �elezioni� all�interno di un certo numero del giornale; o di
<s> all�interno di un determinato <div> (il numero delle
soluzioni corrisponder� al numero dei frasi in quell�articolo).
- le co-occorrenze all�interno di un dato
elemento TEI, oppure all�interno di in una finestra (span) di n
parole. � pertanto possibile cercare co-occorrenze di �modo� e �dire�
all�interno dello stesso articolo o della stessa frase, o in uno span
di 4 parole; oppure co-occorrenze della data �01 aprile� nel
<teiHeader> con la parola �pesce� nel testo, all�interno dello
stesso numero del giornale.
Come risultati di
una ricerca vengono forniti:
- il numero complessivo di soluzioni
- il numero di file nei quali sono
presenti soluzioni
- concordanze che visualizzono le
soluzioni, con un cotesto che pu� essere variato da una frase fino a 2000
caratteri
- per ciascuna soluzione, il nome del file
e il numero della frase in cui compare
E� inoltre possibile:
- definire dei sottocorpora (che possono a
loro volta essere indicizzati);
- interrogare l�indice per sapere quali
parole corrispondono ad un determinato pattern e la frequenza di
ciascuna di esse, escludendo le parole che hanno una frequenza inferiore o
superiore a una determinata soglia;
- calcolare le collocazioni per un
determinato insieme di soluzioni entro uno span specificato,
ottenendo un elenco dei collocati pi� frequenti e/o significativi (z-score
o mutual information). Esiste inoltre la possibilit� di
visualizzare le co-occorrenze dell�espressione con singoli collocati.
3.2������ Alcune ricerche possibili
3.2.1��� Frequenza e distribuzione
Una prima tipologia di dati ricavabili
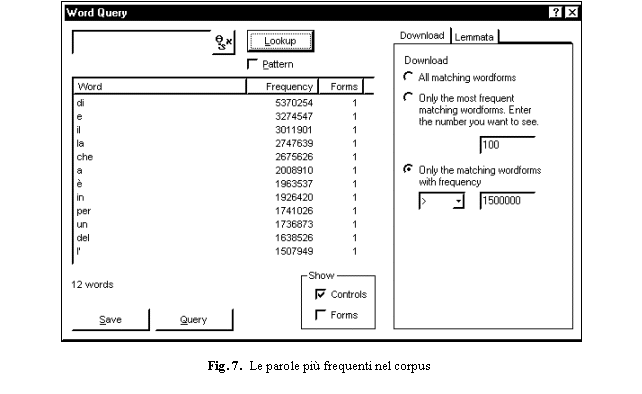
dal corpus riguarda la frequenza delle parole. Qual � la parola pi� frequente?
In Fig. 7 sono elencate le forme che compaiono pi� di 1.500.000 volte nell�indice, ossia pi� di una volta ogni cento
parole.
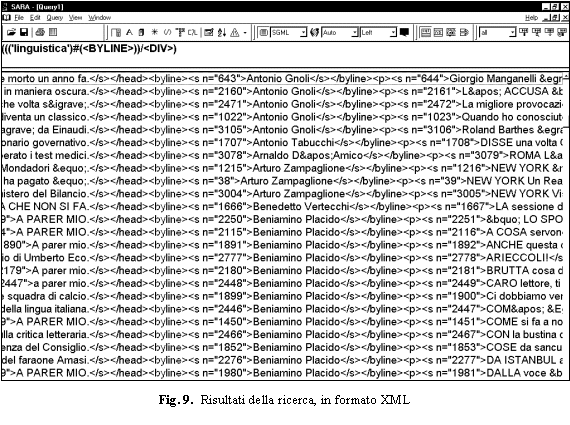
Per conoscere invece la frequenza di una stringa di pi� parole, basta digitarla come quesito. Quante sono le occorrenze di linguistica applicata? Solo una - e neanche questa, si scopre, � un riferimento alla nostra disciplina:
Se l' operazione linguistica applicata al mondo ariostesco di quest' opera che congiunge su un unico schermo teatrale poemi cavallereschi, favole nordiche e storie turchesche, rappresenta l' elemento pi� originale, gli sforzi scaligeri hanno avuto altre questioni da risolvere. (EAH)
Vista la scarsa
presenza dell�applicata, possiamo anche investigare la parola linguistica (801
occorrenze in 519 numeri del giornale), ed esaminare la sua distribuzione nelle
varie annate (Tab. 3):
|
1985 |
1986 |
1987 |
1988 |
1989 |
1990 |
1991 |
|
78 |
77 |
72 |
113 |
170 |
149 |
142 |
Tab. 3. Occorrenze di linguistica
Questi risultati
sembrano suggerire un leggero aumento dell�interesse per la linguistica negli anni in questione, anche se
andrebbero studiati pi� approfonditamente prima di trarne delle conclusioni
certe.
Possiamo anche vedere quali autori parlano di linguistica: "vince"
Beniamino Placido con 42 articoli contenenti la parola linguistica (su
un totale di ben 1551 articoli suoi nei 7 anni presi in considerazione).
Un corpus con
queste caratteristiche permette studi promettenti sulle collocazioni. Le
tabelle elencano le frequenze dei collocati di applauso/applausi in
uno span di 4 parole a sinistra e 4 parole a destra, in ordine di
significativit� decrescente (z-score > 50). Fra i dati potenzialmente
interessanti notiamo l'assenza di forme d del lemma lungo come
collocati della forma plurale (sostituite solo in parte da prolungati),
e l'assenza di forme del lemma fischio come collocati della forma
singolare.
3.2.2��� Collocazioni
3.2.2��� Collocazioni
Un corpus con queste caratteristiche permette studi promettenti sulle collocazioni. Le tabelle elencano le frequenze dei collocati di applauso/applausi in uno span di 4 parole a sinistra e 4 parole a destra, in ordine di significativit� decrescente (z-score > 50). Fra i dati potenzialmente interessanti notiamo l�assenza di forme d del lemma lungo come collocati della forma plurale (sostituite solo in parte da prolungati), e l�assenza di forme del lemma fischio come collocati della forma singolare.
|
|
|
Tab. 4. Collocati di applauso/applausi
3.2.3��� Variazioni fraseologiche
All�interno del sottocorpus per il 1991 ci sono
22 occorrenze della parola cavolo. � un numero sufficientemente piccolo
da consentire un�agevole visualizzazione, e di consequenza un�analisi pi� approfondita delle fraseologie in
cui la parola compare.

Se si ordinano le soluzioni in base alla parola che precede cavolo, si
scopre che il senso metaforico � nettamente pi� frequente di quello letterale,
come era forse prevedibile in testi giornalistici. Cavolo viene
preceduto soprattutto da che (Fig. 10).
Questa concordanza sembrerebbe suggerire che che cavolo vuole/vogliono potrebbe essere una fraseologia ricorrente: tuttavia se cerchiamo nell�intero corpus, troviamo anche altri verbi che accompagnano l�espressione che cavolo con una certa frequenza: dire, entrarci, essere, fare e significare (Fig. 11). Questi esempi sembrano inoltre suggerire un�attribuzione di questa espressione ad un registro parlato - anche se, nel contesto di un quotidiano, sarebbe azzardato ritenere che le citazioni in discorso diretto siano trascrizioni fedeli.

3.2.4��� Posizione all'interno del testo
Negli anni 1985-1991
vengono spesso nominati in La Repubblica due personaggi che vedranno
aumentare la loro popolarit� negli anni successivi: Romano Prodi e Silvio
Berlusconi. La tabella seguente riporta le frequenze su base annuale - �
evidente un declino di Prodi negli ultimi anni - e la posizione occupata da
questi nomi all�interno della
frase:
|
|
Prodi |
Berlusconi |
||||
|
|
totale |
inizio frase |
fine frase |
totale |
inizio frase |
fine frase |
|
1985 |
703 |
65 (9%) |
59 (8%) |
635 |
40 (6%) |
97 (15%) |
|
1986 |
664 |
52 (8%) |
63 (9%) |
1330 |
123 (9%) |
196 (15%) |
|
1987 |
831 |
100 (12%) |
106 (13%) |
1508 |
140 (9%) |
235 (16%) |
|
1988 |
894 |
95 (11%) |
88 (10%) |
1745 |
155 (9%) |
261 (15%) |
|
1989 |
780 |
90 (12%) |
81 (10%) |
2376 |
206 (9%) |
343 (14%) |
|
1990 |
182 |
13 (7%) |
25 (14%) |
2434 |
202 (8%) |
390 (16%) |
|
1991 |
123 |
9 (7%) |
12 (10%) |
1583 |
113 (7%) |
202 (13%) |
|
Totale |
4177 |
424 (10%) |
434 (10%) |
11611 |
979 (8%) |
1724 (15%) |
Tab. 5. Prodi e Berlusconi:
frequenze e posizioni sintattiche
Data la lunghezza media della frase nel corpus (22 parole), ci si aspetterebbe (in base ad una distribuzione casuale) che il 5% circa delle occorrenze risultassero come prima parola, e il 5% come ultima parola della frase. Le percentuali sono sempre pi� alte - un fatto che non sorprender�, forse, nessun studioso di grammatica. Colpisce invece che mentre Prodi compare con frequenze simili come prima e come ultima parola, Berlusconi mostra una nettissima tendenza a concludere la frase - una tendenza che rimane costante lungo tutto l�arco di tempo esaminato. Lasciamo al lettore l�eventuale interpretazione di questo dato in chiave storico-linguistica.
4��������� Conclusioni
I primi sette anni
del corpus de La Repubblica (1985-1991) sono ormai funzionanti con il
nome di Reptry sul server della SSLMIT (einstein.sslmit.unibo.it; port
7003). Per accedere al corpus � necessario essere in possesso di:
- un collegamento Internet;
- l�ultima versione del programma client
di SARA, scaricabile gratuitamente dal sito
http://www.hcu.ox.ac.uk/BNC/SARA/version.html;
- uno username e una password,
che vengono forniti gratuitamente per un periodo massimo di 12 mesi
(rinnovabile) ai colleghi che si impegnino per iscritto ad utilizzare il
corpus per soli fini di didattica e di ricerca. Le richieste vanno
inoltrate a repubblica@sslmit.unibo.it.
Nei prossimi mesi speriamo di completare il corpus, con l�aggiunta dei
nove anni rimanenti (1992-2000). In futuro, qualora si renderanno disponibili
le risorse necessarie, vorremmo inoltre:
- codificare ogni parola in base alla
relativa categoria morfosintattica. A tal scopo sar� necessario reperire
un tagger automatico di sufficiente affidabilit�, tenendo presente
il grande numero di nomi propri e espressioni straniere presenti;
- lemmatizzare l�indice, in modo da
permettere ricerche di qualsiasi forma di un determinato lemma (con
l�affissione di clitici, il numero di forme diverse pu� raggiungere in
alcuni casi il centinaio). A tal fine � necessario reperire un lessico
elettronico per l�italiano
che elenchi tutte le forme possibili per ciascun lemma, nonch� un insieme
di regole per la lemmatizzazione di forme non comprese in tale elenco;
- introdurre una categorizzazione degli
articoli, in modo da permettere ricerche all�interno di determinati campi
(interni, esteri, cronaca, sport, cultura ecc.). Non essendo proponibile
una categorizzazione manuale, bisogner� identificare o creare uno
strumento automatico adatto, ad esempio ipotizzando che tutti gli articoli
sulla medesima pagina interna rientrino normalmente nella stessa
categoria, e che articoli appartenenti a categorie diverse presentino,
mediamente, delle caratteristiche testuali e lessicogrammaticali diverse (Biber
1988).
Bibliografia
Aston G. & Burnard
L., The BNC handbook: exploring the British National
Corpus with SARA, Edinburgh University Press, Edinburgh, 1998.
Bernardini S. & Zanettin F. (a cura di), I corpora
nella didattica della traduzione, Cooperativa Libraria Universitaria
Editrice, Bologna, 2000.
Biber D, Variation across speech and writing, Cambridge University
Press, Cambridge, 1988.
Rossini Favretti R., Tamburini F. & De Santis C.,
A corpus of written Italian: a defined and a dynamic model, in A. Wilson, P. Rayson & T. McEnery
(eds.), A rainbow of corpora: corpus linguistics and the languages of the
world, Lincom-Europa, M�nich,
in stampa.
Sperberg-McQueen, C.M. & Burnard L.
(eds), Guidelines for text encoding and interchange (P4), Humanities Computing Unit, Oxford University, Oxford,
2002.
Guy Aston
e-mail
<guy@sslmit.unibo.it>
Lorenzo Piccioni
e-mail <lpiccio@sslmit.unibo.it>